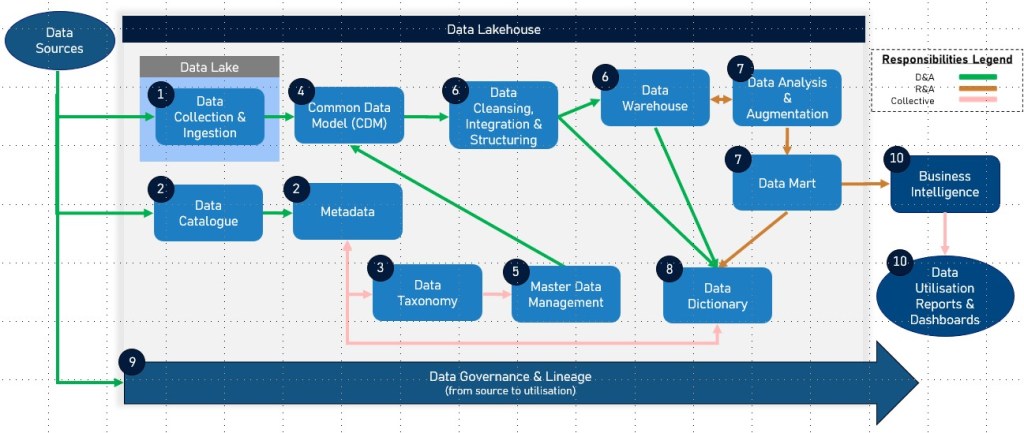
The AI field is rapidly evolving, with several key trends shaping the future of data analysis and the broader landscape of technology and business. Here’s a concise overview of some of the latest trends:
Shift Towards Smaller, Explainable AI Models: There’s a growing trend towards developing smaller, more efficient AI models that can run on local devices such as smartphones, facilitating edge computing and Internet of Things (IoT) applications. These models address privacy and cybersecurity concerns more effectively and are becoming easier to understand and trust due to advancements in explainable AI. This shift is partly driven by necessity, owing to increasing cloud computing costs and GPU shortages, pushing for optimisation and accessibility of AI technologies.
This trend has the capacity to significantly lower the barrier to entry for smaller enterprises wishing to implement AI solutions, democratising access to AI technologies. By enabling AI to run efficiently on local devices, it opens up new possibilities for edge computing and IoT applications in sectors such as healthcare, manufacturing, and smart cities, whilst also addressing crucial privacy and cybersecurity concerns.
Generative AI’s Promise and Challenges: Generative AI has captured significant attention but remains in the phase of proving its economic value. Despite the excitement and investment in this area, with many companies exploring its potential, actual production deployments that deliver substantial value are still few. This underscores a critical period of transition from experimentation to operational integration, necessitating enhancements in data strategies and organisational changes.
Generative AI holds transformative potential across creative industries, content generation, design, and more, offering the capability to create highly personalised content at scale. However, its economic viability and ethical implications, including the risks of deepfakes and misinformation, present significant challenges that need to be navigated.
From Artisanal to Industrial Data Science: The field of data science is becoming more industrialised, moving away from an artisanal approach. This shift involves investing in platforms, processes, and tools like MLOps systems to increase the productivity and deployment rates of data science models. Such changes are facilitated by external vendors, but some organisations are developing their own platforms, pointing towards a more systematic and efficient production of data models.
The industrialisation of data science signifies a shift towards more scalable, efficient data processing and model development processes. This could disrupt traditional data analysis roles and demand new skills and approaches to data science work, potentially leading to increased automation and efficiency in insights generation.
The Democratisation of AI: Tools like ChatGPT have played a significant role in making AI technologies more accessible to a broader audience. This democratisation is characterised by easy access, user-friendly interfaces, and affordable or free usage. Such trends not only bring AI tools closer to users but also open up new opportunities for personal and business applications, reshaping the cultural understanding of media and communication.
Making AI more accessible to a broader audience has the potential to spur innovation across various sectors by enabling more individuals and businesses to apply AI solutions to their problems. This could lead to new startups and business models that leverage AI in novel ways, potentially disrupting established markets and industries.
Emergence of New AI-Driven Occupations and Skills: As AI technologies evolve, new job roles and skill requirements are emerging, signalling a transformation in the workforce landscape. This includes roles like prompt engineers, AI ethicists, and others that don’t currently exist but are anticipated to become relevant. The ongoing integration of AI into various industries underscores the need for reskilling and upskilling to thrive in this changing environment.
As AI technologies evolve, they will create new job roles and transform existing ones, disrupting the job market and necessitating significant shifts in workforce skills and education. Industries will need to adapt to these changes by investing in reskilling and upskilling initiatives to prepare for future job landscapes.
Personalisation at Scale: AI is enabling unprecedented levels of personalisation, transforming communication from mass messaging to niche, individual-focused interactions. This trend is evident in the success of platforms like Netflix, Spotify, and TikTok, which leverage sophisticated recommendation algorithms to deliver highly personalised content.
AI’s ability to enable personalisation at unprecedented levels could significantly impact retail, entertainment, education, and marketing, offering more tailored experiences to individuals and potentially increasing engagement and customer satisfaction. However, it also raises concerns about privacy and data security, necessitating careful consideration of ethical and regulatory frameworks.
Augmented Analytics: Augmented analytics is emerging as a pivotal trend in the landscape of data analysis, combining advanced AI and machine learning technologies to enhance data preparation, insight generation, and explanation capabilities. This approach automates the process of turning vast amounts of data into actionable insights, empowering analysts and business users alike with powerful analytical tools that require minimal technical expertise.
The disruptive potential of augmented analytics lies in its ability to democratize data analytics, making it accessible to a broader range of users within an organization. By reducing reliance on specialized data scientists and significantly speeding up decision-making processes, augmented analytics stands to transform how businesses strategize, innovate, and compete in increasingly data-driven markets. Its adoption can lead to more informed decision-making across all levels of an organization, fostering a culture of data-driven agility that can adapt to changes and discover opportunities in real-time.
Decision Intelligence: Decision Intelligence represents a significant shift in how organizations approach decision-making, blending data analytics, artificial intelligence, and decision theory into a cohesive framework. This trend aims to improve decision quality across all sectors by providing a structured approach to solving complex problems, considering the myriad of variables and outcomes involved.
The disruptive potential of Decision Intelligence lies in its capacity to transform businesses into more agile, informed entities that can not only predict outcomes but also understand the intricate web of cause and effect that leads to them. By leveraging data and AI to map out potential scenarios and their implications, organizations can make more strategic, data-driven decisions. This approach moves beyond traditional analytics by integrating cross-disciplinary knowledge, thereby enhancing strategic planning, operational efficiency, and risk management. As Decision Intelligence becomes more embedded in organizational processes, it could significantly alter competitive dynamics by privileging those who can swiftly adapt to and anticipate market changes and consumer needs.
Quantum Computing: The future trend of integrating quantum computers into AI and data analytics signals a paradigm shift with profound implications for processing speed and problem-solving capabilities. Quantum computing, characterised by its ability to process complex calculations exponentially faster than classical computers, is poised to unlock new frontiers in AI and data analytics. This integration could revolutionise areas requiring massive computational power, such as simulating molecular interactions for drug discovery, optimising large-scale logistics and supply chains, or enhancing the capabilities of machine learning models. By harnessing quantum computers, AI systems could analyse data sets of unprecedented size and complexity, uncovering insights and patterns beyond the reach of current technologies. Furthermore, quantum-enhanced machine learning algorithms could learn from data more efficiently, leading to more accurate predictions and decision-making processes in real-time. As research and development in quantum computing continue to advance, its convergence with AI and data analytics is expected to catalyse a new wave of innovations across various industries, reshaping the technological landscape and opening up possibilities that are currently unimaginable.
The disruptive potential of quantum computing for AI and Data Analytics is profound, promising to reshape the foundational structures of these fields. Quantum computing operates on principles of quantum mechanics, enabling it to process complex computations at speeds unattainable by classical computers. This leap in computational capabilities opens up new horizons for AI and data analytics in several key areas:
- Complex Problem Solving: Quantum computing can efficiently solve complex optimisation problems that are currently intractable for classical computers. This could revolutionise industries like logistics, where quantum algorithms optimise routes and supply chains, or finance, where they could be used for portfolio optimisation and risk analysis at a scale and speed previously unimaginable.
- Machine Learning Enhancements: Quantum computing has the potential to significantly enhance machine learning algorithms through quantum parallelism. This allows for the processing of vast datasets simultaneously, making the training of machine learning models exponentially faster and potentially more accurate. It opens the door to new AI capabilities, from more sophisticated natural language processing systems to more accurate predictive models in healthcare diagnostics.
- Drug Discovery and Material Science: Quantum computing could dramatically accelerate the discovery of new drugs and materials by simulating molecular and quantum systems directly. For AI and data analytics, this means being able to analyse and understand complex chemical reactions and properties that were previously beyond reach, leading to faster innovation cycles in pharmaceuticals and materials engineering.
- Data Encryption and Security: The advent of quantum computing poses significant challenges to current encryption methods, potentially rendering them obsolete. However, it also introduces quantum cryptography, providing new ways to secure data transmission—a critical aspect of data analytics in maintaining the privacy and integrity of data.
- Big Data Processing: The sheer volume of data generated today poses significant challenges in storage, processing, and analysis. Quantum computing could enable the processing of this “big data” in ways that extract more meaningful insights in real-time, enhancing decision-making processes in business, science, and government.
- Enhancing Simulation Capabilities: Quantum computers can simulate complex systems much more efficiently than classical computers. This capability could be leveraged in AI and data analytics to create more accurate models of real-world phenomena, from climate models to economic simulations, leading to better predictions and strategies.
The disruptive potential of quantum computing in AI and data analytics lies in its ability to process information in fundamentally new ways, offering solutions to currently unsolvable problems and significantly accelerating the development of new technologies and innovations. However, the realisation of this potential is contingent upon overcoming significant technical challenges, including error rates and qubit coherence times. As research progresses, the integration of quantum computing into AI and data analytics could herald a new era of technological advancement and innovation.
Practical Examples of these Trends
Some notable examples where the latest trends in AI are already being put into practice. These highlight the practical applications of the latest trends in AI, including the development of smaller, more efficient AI models, the push towards open and responsible AI development, and the innovative use of APIs and energy networking to leverage AI’s benefits more sustainably and effectiv:
- Smaller AI Models in Business Applications: Inflection’s Pi chatbot upgrade to the new Inflection 2.5 model is a prime example of smaller, more cost-effective AI models making advanced AI more accessible to businesses. This model achieves close to GPT-4’s effectiveness with significantly lower computational resources, demonstrating that smaller language models can still deliver strong performance efficiently. Businesses like Dialpad and Lyric are exploring these smaller, customizable models for various applications, highlighting a broader industry trend towards efficient, scalable AI solutions.
- Google’s Gemma Models for Open and Responsible AI Development: Google introduced Gemma, a family of lightweight, open models built for responsible AI development. Available in two sizes, Gemma 2B and Gemma 7B, these models are designed to be accessible and efficient, enabling developers and researchers to build AI responsibly. Google also released a Responsible Generative AI Toolkit alongside Gemma models, supporting a safer and more ethical approach to AI application development. These models can run on standard hardware and are optimized for performance across multiple AI platforms, including NVIDIA GPUs and Google Cloud TPUs.
- API-Driven Customization and Energy Networking for AI: Cisco’s insights into the future of AI-driven customization and the emerging field of energy networking reflect a strategic approach to leveraging AI. The idea of API abstraction, acting as a bridge to integrate a multitude of pre-built AI tools and services, is set to empower businesses to leverage AI’s benefits without the complexity and cost of building their own platforms. Moreover, the concept of energy networking combines software-defined networking with electric power systems to enhance energy efficiency, demonstrating an innovative approach to managing the energy consumption of AI technologies.
- Augmented Analytics: An example of augmented analytics in action is the integration of AI-driven insights into customer relationship management (CRM) systems. Consider a company using a CRM system enhanced with augmented analytics capabilities to analyze customer data and interactions. This system can automatically sift through millions of data points from emails, call transcripts, purchase histories, and social media interactions to identify patterns and trends. For instance, it might uncover that customers from a specific demographic tend to churn after six months without engaging in a particular loyalty program. Or, it could predict which customers are most likely to upgrade their services based on their interaction history and product usage patterns. By applying machine learning models, the system can generate recommendations for sales teams on which customers to contact, the best time for contact, and even suggest personalized offers that are most likely to result in a successful upsell. This level of analysis and insight generation, which would be impractical for human analysts to perform at scale, allows businesses to make data-driven decisions quickly and efficiently. Sales teams can focus their efforts more strategically, marketing can tailor campaigns with precision, and customer service can anticipate issues before they escalate, significantly enhancing the customer experience and potentially boosting revenue.
- Decision Intelligence: An example of Decision Intelligence in action can be observed in the realm of supply chain management for a large manufacturing company. Facing the complex challenge of optimizing its supply chain for cost, speed, and reliability, the company implements a Decision Intelligence platform. This platform integrates data from various sources, including supplier performance records, logistics costs, real-time market demand signals, and geopolitical risk assessments. Using advanced analytics and machine learning, the platform models various scenarios to predict the impact of different decisions, such as changing suppliers, altering transportation routes, or adjusting inventory levels in response to anticipated market demand changes. For instance, it might reveal that diversifying suppliers for critical components could reduce the risk of production halts due to geopolitical tensions in a supplier’s region, even if it slightly increases costs. Alternatively, it could suggest reallocating inventory to different warehouses to mitigate potential delivery delays caused by predicted shipping disruptions. By providing a comprehensive view of potential outcomes and their implications, the Decision Intelligence platform enables the company’s leadership to make informed, strategic decisions that balance cost, risk, and efficiency. Over time, the system learns from past outcomes to refine its predictions and recommendations, further enhancing the company’s ability to navigate the complexities of global supply chain management. This approach not only improves operational efficiency and resilience but also provides a competitive advantage in rapidly changing markets.
- Quantum Computing: One real-world example of the emerging intersection between quantum computing, AI, and data analytics is the collaboration between Volkswagen and D-Wave Systems on optimising traffic flow for public transportation systems. This project aimed to leverage quantum computing’s power to reduce congestion and improve the efficiency of public transport in large metropolitan areas. In this initiative, Volkswagen used D-Wave’s quantum computing capabilities to analyse and optimise the traffic flow of taxis in Beijing, China. The project involved processing vast amounts of GPS data from approximately 10,000 taxis operating within the city. The goal was to develop a quantum computing-driven algorithm that could predict traffic congestion and calculate the fastest routes in real-time, considering various factors such as current traffic conditions and the most efficient paths for multiple vehicles simultaneously. By applying quantum computing to this complex optimisation problem, Volkswagen was able to develop a system that suggested optimal routes, potentially reducing traffic congestion and decreasing the overall travel time for public transport vehicles. This not only illustrates the practical application of quantum computing in solving real-world problems but also highlights its potential to revolutionise urban planning and transportation management through enhanced data analytics and AI-driven insights. This example underscores the disruptive potential of quantum computing in AI and data analytics, demonstrating how it can be applied to tackle large-scale, complex challenges that classical computing approaches find difficult to solve efficiently.
Conclusion
These trends indicate a dynamic period of growth and challenge for the AI field, with significant implications for data analysis, business strategies, and societal interactions. As AI technologies continue to develop, their integration into various domains will likely create new opportunities and require adaptations in how we work, communicate, and engage with the digital world.
Together, these trends highlight a future where AI integration becomes more widespread, efficient, and personalised, leading to significant economic, societal, and ethical implications. Businesses and policymakers will need to navigate these changes carefully, considering both the opportunities and challenges they present, to harness the disruptive potential of AI positively.