Data lineage refers to the lifecycle of data as it travels through various processes in an information system. It is a comprehensive account or visualisation of where data originates, where it moves, and how it changes throughout its journey within an organisation. Essentially, data lineage provides a clear map or trace of the data’s journey from its source to its destination, including all the transformations it undergoes along the way.
Here are some key aspects of data lineage:
Source of Data: Data lineage begins by identifying the source of the data, whether it’s from internal databases, external data sources, or real-time data streams.
Data Transformations: It records each process or transformation the data undergoes, such as data cleansing, aggregation, and merging. This helps in understanding how the data is manipulated and refined.
Data Movement: The path that data takes through different systems and processes is meticulously traced. This includes its movement across databases, servers, and applications within an organisation.
Final Destination: Data lineage includes tracking the data to its final destination, which might be a data warehouse, report, or any other endpoint where the data is stored or utilised.
Importance of Data Lineage
Data lineage is crucial for several reasons:
Transparency and Trust: It helps build confidence in data quality and accuracy by providing transparency on how data is handled and transformed.
Compliance and Auditing: Many industries are subject to stringent regulatory requirements concerning data handling, privacy, and reporting. Data lineage allows for compliance tracking and simplifies the auditing process by providing a clear trace of data handling practices.
Error Tracking and Correction: By understanding how data flows through systems, it becomes easier to identify the source of errors or discrepancies and correct them, thereby improving overall data quality.
Impact Analysis: Data lineage is essential for impact analysis, enabling organisations to assess the potential effects of changes in data sources or processing algorithms on downstream systems and processes.
Data Governance: Effective data governance relies on clear data lineage to enforce policies and rules regarding data access, usage, and security.
Tooling
Data lineage tools are essential for tracking the flow of data through various systems and transformations, providing transparency and facilitating better data management practices. Here’s a list of popular technology tools that can be used for data lineage:
Informatica: A leader in data integration, Informatica offers powerful tools for managing data lineage, particularly with its Enterprise Data Catalogue, which helps organisations to discover and inventory data assets across the system.
IBM InfoSphere Information Governance Catalogue: IBM’s solution provides extensive features for data governance, including data lineage. It helps users understand data origin, usage, and transformation within their enterprise environments.
Talend: Talend’s Data Fabric includes data lineage capabilities that help map and visualise the flow of data through different systems, helping with compliance, data governance, and data quality management.
Collibra: Collibra is known for its data governance and catalogue software that supports data lineage visualisation to manage compliance, data quality, and data usage across the organisation.
Apache Atlas: Part of the Hadoop ecosystem, Apache Atlas provides open-source tools for metadata management and data governance, including data lineage for complex data environments.
Alation: Alation offers a data catalogue tool that includes data lineage features, providing insights into data origin, context, and usage, which is beneficial for data governance and compliance.
MANTA: MANTA focuses specifically on data lineage and provides visualisation tools that help organisations map out and understand their data flows and transformations.
erwin Data Intelligence: erwin provides robust data modelling and metadata management solutions, including data lineage tools to help organisations understand the flow of data within their IT ecosystems.
Microsoft Purview: This is a unified data governance service that helps manage and govern on-premises, multi-cloud, and software-as-a-service (SaaS) data. It includes automated data discovery, sensitivity classification, access controls and end-to-end data lineage.
Google Cloud Data Catalogue: A fully managed and scalable metadata management service that allows organisations to quickly discover, manage, and understand their Google Cloud data assets. It includes data lineage capabilities to visualise relationships and data flows.
These tools cater to a variety of needs, from large enterprises to more specific requirements like compliance and data quality management. They can help organisations ensure that their data handling practices are transparent, efficient, and compliant with relevant regulations.
In summary, data lineage acts as a critical component of data management and governance frameworks, providing a clear and accountable method of tracking data from its origin through all its transformations and uses. This tracking is indispensable for maintaining the integrity, reliability, and trustworthiness of data in complex information systems.
Introduction: The Importance of Data Cataloguing in Modern Business
With big data now mainstream, managing vast amounts of information has become a critical challenge for businesses across the globe. Effective data management transcends mere data storage, focusing equally on accessibility and governability. “Data cataloguing is critical because it not only organizes data but also makes it accessible and actionable,” notes Susan White, a renowned data management strategist. This process is a vital component of any robust data management strategy.
Today, we’ll explore the necessary steps to establish a successful data catalogue. We’ll also highlight some industry-leading tools that can help streamline this complex process. “A well-implemented data catalogue is the backbone of data-driven decision-making,” adds Dr. Raj Singh, an expert in data analytics. “It provides the transparency needed for businesses to effectively use their data, ensuring compliance and enhancing operational efficiency.”
By integrating these expert perspectives, we aim to provide a comprehensive overview of how data cataloguing can significantly benefit your organization, supporting more informed decision-making and strategic planning.
Understanding Data Cataloguing
Data cataloguing involves creating a central repository that organises, manages, and maintains an organisation’s data to make it easily discoverable and usable. It not only enhances data accessibility but also supports compliance and governance, making it an indispensable tool for businesses.
Step-by-Step Guide to Data Cataloguing
1. Define Objectives and Scope
Firstly, identify what you aim to achieve with your data catalogue. Goals may include compliance, improved data discovery, or better data governance. Decide on the scope – whether it’s for the entire enterprise or specific departments.
2. Gather Stakeholder Requirements
Involve stakeholders such as data scientists, IT professionals, and business analysts early in the process. Understanding their needs – from search capabilities to data lineage – is crucial for designing a functional catalogue.
3. Choose the Right Tools
Selecting the right tools is critical for effective data cataloguing. Consider platforms like Azure Purview, which offers extensive metadata management and governance capabilities within the Microsoft ecosystem. For those embedded in the Google Cloud Platform, Google Cloud Data Catalog provides powerful search functionalities and automated schema management. Meanwhile, AWS Glue Data Catalog is a great choice for AWS users, offering seamless integration with other AWS services. More detail on tooling below.
4. Develop a Data Governance Framework
Set clear policies on who can access and modify the catalogue. Standardise how metadata is collected, stored, and updated to ensure consistency and reliability.
5. Collect and Integrate Data
Document all data sources and use automation tools to extract metadata. This step reduces manual errors and saves significant time.
6. Implement Metadata Management
Decide on the types of metadata to catalogue (technical, business, operational) and ensure consistency in its description and format.
Business Metadata: This type of metadata provides context to data by defining commonly used terms in a way that is independent of technical implementation. The Data Management Body of Knowledge (DMBoK) notes that business metadata primarily focuses on the nature and condition of the data, incorporating elements related to Data Governance.
Technical Metadata: This metadata supplies computer systems with the necessary information about data’s format and structure. It includes details such as physical database tables, access restrictions, data models, backup procedures, mapping specifications, data lineage, and more.
Operational Metadata: As defined by the DMBoK, operational metadata pertains to the specifics of data processing and access. This includes information such as job execution logs, data sharing policies, error logs, audit trails, maintenance plans for multiple versions, archiving practices, and retention policies.
7. Populate the Catalogue
Use automated tools (see section on tooling below) and manual processes to populate the catalogue. Regularly verify the integrity of the data to ensure accuracy.
8. Enable Data Discovery and Access
A user-friendly interface is key to enhancing engagement and making data discovery intuitive. Implement robust security measures to protect sensitive information.
9. Train Users
Provide comprehensive training and create detailed documentation to help users effectively utilise the catalogue.
10. Monitor and Maintain
Keep the catalogue updated with regular reviews and revisions. Establish a feedback loop to continuously improve functionality based on user input.
11. Evaluate and Iterate
Use metrics to assess the impact of the catalogue and make necessary adjustments to meet evolving business needs.
Data Catalogue’s Value Proposition
Data catalogues are critical assets in modern data management, helping businesses harness the full potential of their data. Here are several real-life examples illustrating how data catalogues deliver value to businesses across various industries:
Financial Services: Improved Compliance and Risk Management – A major bank implemented a data catalogue to manage its vast data landscape, which includes data spread across different systems and geographies. The data catalogue enabled the bank to enhance its data governance practices, ensuring compliance with global financial regulations such as GDPR and SOX. By providing a clear view of where and how data is stored and used, the bank was able to effectively manage risks and respond to regulatory inquiries quickly, thus avoiding potential fines and reputational damage.
Healthcare: Enhancing Patient Care through Data Accessibility – A large healthcare provider used a data catalogue to centralise metadata from various sources, including electronic health records (EHR), clinical trials, and patient feedback systems. This centralisation allowed healthcare professionals to access and correlate data more efficiently, leading to better patient outcomes. For instance, by analysing a unified view of patient data, researchers were able to identify patterns that led to faster diagnoses and more personalised treatment plans.
Retail: Personalisation and Customer Experience Enhancement – A global retail chain implemented a data catalogue to better manage and analyse customer data collected from online and in-store interactions. With a better-organised data environment, the retailer was able to deploy advanced analytics to understand customer preferences and shopping behaviour. This insight enabled the retailer to offer personalised shopping experiences, targeted marketing campaigns, and optimised inventory management, resulting in increased sales and customer satisfaction.
Telecommunications: Network Optimisation and Fraud Detection – A telecommunications company utilised a data catalogue to manage data from network traffic, customer service interactions, and billing systems. This comprehensive metadata management facilitated advanced analytics applications for network optimisation and fraud detection. Network engineers were able to predict and mitigate network outages before they affected customers, while the fraud detection teams used insights from integrated data sources to identify and prevent billing fraud effectively.
Manufacturing: Streamlining Operations and Predictive Maintenance – In the manufacturing sector, a data catalogue was instrumental for a company specialising in high-precision equipment. The catalogue helped integrate data from production line sensors, machine logs, and quality control to create a unified view of the manufacturing process. This integration enabled predictive maintenance strategies that reduced downtime by identifying potential machine failures before they occurred. Additionally, the insights gained from the data helped streamline operations, improve product quality, and reduce waste.
These examples highlight how a well-implemented data catalogue can transform data into a strategic asset, enabling more informed decision-making, enhancing operational efficiencies, and creating a competitive advantage in various industry sectors.
A data catalog is an organized inventory of data assets in an organization, designed to help data professionals and business users find and understand data. It serves as a critical component of modern data management and governance frameworks, facilitating better data accessibility, quality, and understanding. Below, we discuss the key components of a data catalog and provide examples of the types of information and features that are typically included.
Key Components of a Data Catalog
Metadata Repository
Description: The core of a data catalog, containing detailed information about various data assets.
Examples: Metadata could include the names, types, and descriptions of datasets, data schemas, tables, and fields. It might also contain tags, annotations, and extended properties like data type, length, and nullable status.
Data Dictionary
Description: A descriptive list of all data items in the catalog, providing context for each item.
Examples: For each data element, the dictionary would provide a clear definition, source of origin, usage guidelines, and information about data sensitivity and ownership.
Data Lineage
Description: Visualization or documentation that explains where data comes from, how it moves through systems, and how it is transformed.
Examples: Lineage might include diagrams showing data flow from one system to another, transformations applied during data processing, and dependencies between datasets.
Search and Discovery Tools
Description: Mechanisms that allow users to easily search for and find data across the organization.
Examples: Search capabilities might include keyword search, faceted search (filtering based on specific attributes), and full-text search across metadata descriptions.
User Interface
Description: The front-end application through which users interact with the data catalog.
Examples: A web-based interface that provides a user-friendly dashboard to browse, search, and manage data assets.
Access and Security Controls
Description: Features that manage who can view or edit data in the catalog.
Examples: Role-based access controls that limit users to certain actions based on their roles, such as read-only access for some users and edit permissions for others.
Integration Capabilities
Description: The ability of the data catalog to integrate with other tools and systems in the data ecosystem.
Examples: APIs that allow integration with data management tools, BI platforms, and data lakes, enabling automated metadata updates and interoperability.
Quality Metrics
Description: Measures and indicators related to the quality of data.
Examples: Data quality scores, reports on data accuracy, completeness, consistency, and timeliness.
Usage Tracking and Analytics
Description: Tools to monitor how and by whom the data assets are accessed and used.
Examples: Logs and analytics that track user queries, most accessed datasets, and patterns of data usage.
Collaboration Tools
Description: Features that facilitate collaboration among users of the data catalog.
Examples: Commenting capabilities, user forums, and shared workflows that allow users to discuss data, share insights, and collaborate on data governance tasks.
Organisational Framework and Structure
The structure of an organisation itself is not typically a direct component of a data catalog. However, understanding and aligning the data catalog with the organizational structure is crucial for several reasons:
Role-Based Access Control: The data catalog often needs to reflect the organizational hierarchy or roles to manage permissions effectively. This involves setting up access controls that align with job roles and responsibilities, ensuring that users have appropriate access to data assets based on their position within the organization.
Data Stewardship and Ownership: The data catalog can include information about data stewards or owners who are typically assigned according to the organizational structure. These roles are responsible for the quality, integrity, and security of the data, and they often correspond to specific departments or business units.
Customization and Relevance: The data catalog can be customized to meet the specific needs of different departments or teams within the organization. For instance, marketing data might be more accessible and prominently featured for the marketing department in the catalog, while financial data might be prioritized for the finance team.
Collaboration and Communication: Understanding the organizational structure helps in designing the collaboration features of the data catalog. It can facilitate better communication and data sharing practices among different parts of the organization, promoting a more integrated approach to data management.
In essence, while the organisational structure isn’t stored as a component in the data catalog, it profoundly influences how the data catalog is structured, accessed, and utilised. The effectiveness of a data catalog often depends on how well it is tailored and integrated into the organizational framework, helping ensure that the right people have the right access to the right data at the right time.
Example of a Data Catalog in Use
Imagine a large financial institution that uses a data catalog to manage its extensive data assets. The catalog includes:
Metadata Repository: Contains information on thousands of datasets related to transactions, customer interactions, and compliance reports.
Data Dictionary: Provides definitions and usage guidelines for key financial metrics and customer demographic indicators.
Data Lineage: Shows the flow of transaction data through various security and compliance checks before it is used for reporting.
Search and Discovery Tools: Enable analysts to find and utilize specific datasets for developing insights into customer behavior and market trends.
Quality Metrics: Offer insights into the reliability of datasets used for critical financial forecasting.
By incorporating these components, the institution ensures that its data is well-managed, compliant with regulations, and effectively used to drive business decisions.
Tiveness of a data catalog often depends on how well it is tailored and integrated into the organisational framework, helping ensure that the right people have the right access to the right data at the right time.
Tooling
For organizations looking to implement data cataloging in cloud environments, the major cloud providers – Azure, Google Cloud Platform (GCP), and Amazon Web Services (AWS) – each offer their own specialised tools.
Here’s a comparison table that summarises the key features, descriptions, and use cases of data cataloging tools offered by Azure, Google Cloud Platform (GCP), and Amazon Web Services (AWS):
Feature
Azure Purview
Google Cloud Data Catalog
AWS Glue Data Catalog
Description
A unified data governance service that automates the discovery of data and cataloging. It helps manage and govern on-premise, multi-cloud, and SaaS data.
A fully managed and scalable metadata management service that enhances data discovery and understanding within Google Cloud.
A central repository that stores structural and operational metadata, integrating with other AWS services.
Key Features
– Automated data discovery and classification. – Data lineage for end-to-end data insight. – Integration with Azure services like Azure Data Lake, SQL Database, and Power BI.
– Metadata storage for Google Cloud and external data sources. – Advanced search functionality using Google Search technology. – Automatic schema management and discovery.
– Automatic schema discovery and generation. – Serverless design, scales with data. – Integration with AWS services like Amazon Athena, Amazon EMR, and Amazon Redshift.
Use Case
Best for organizations deeply integrated into the Microsoft ecosystem, seeking comprehensive governance and compliance capabilities.
Ideal for businesses using multiple Google Cloud services, needing a simple, integrated approach to metadata management.
Suitable for AWS-centric environments that require a robust, scalable solution for ETL jobs and data querying.
Data Catalogue Tooling Comparison
This table provides a quick overview to help you compare the offerings and decide which tool might be best suited for your organizational needs based on the environment you are most invested in.
Conclusion
Implementing a data catalogue can dramatically enhance an organisation’s ability to manage data efficiently. By following these steps and choosing the right tools, businesses can ensure their data assets are well-organised, easily accessible, and securely governed. Whether you’re part of a small team or a large enterprise, embracing these practices can lead to more informed decision-making and a competitive edge in today’s data-driven world.
In the contemporary landscape of data-driven decision-making, robust data management practices are critical for organisations seeking to harness the full potential of their data assets. Effective data management encompasses various components, each playing a vital role in ensuring data integrity, accessibility, and usability.
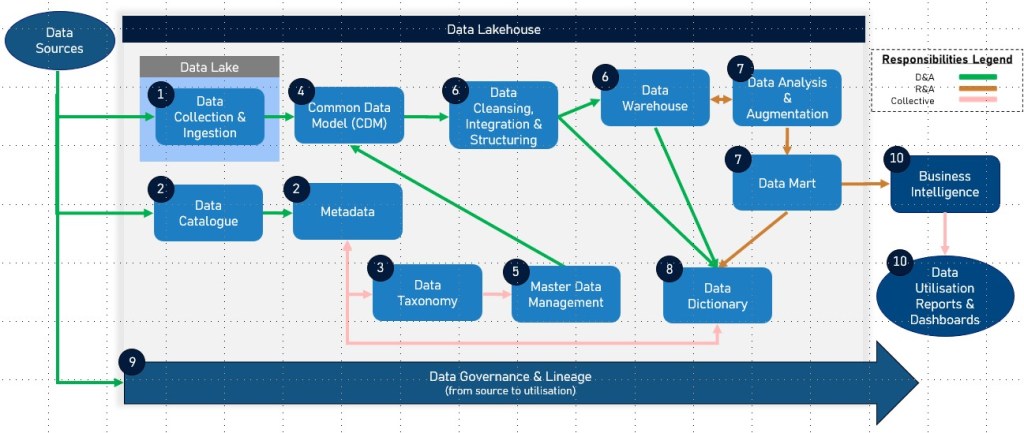
Key components such as data catalogues, taxonomies, common data models, data dictionaries, master data, data lineage, data lakes, data warehouses, data lakehouses, and data marts, along with their interdependencies and sequences within the data lifecycle, form the backbone of a sound data management strategy.
This cocise guide explores these components in detail, elucidating their definitions, uses, and how they interrelate to support seamless data management throughout the data lifecycle.
Definitions and Usage of Key Data Management Components
Data Catalogue
Definition: A data catalogue is a comprehensive inventory of data assets within an organisation. It provides metadata, data classification, and information on data lineage, data quality, and data governance.
Usage: Data catalogues help data users discover, understand, and manage data. They enable efficient data asset management and ensure compliance with data governance policies.
Data Taxonomy
Definition: Data taxonomy is a hierarchical structure that organises data into categories and subcategories based on shared characteristics or business relevance.
Usage: It facilitates data discovery, improves data quality, and aids in the consistent application of data governance policies by providing a clear structure for data classification.
Data Dictionary
Definition: A data dictionary is a centralised repository that describes the structure, content, and relationships of data elements within a database or information system.
Usage: Data dictionaries provide metadata about data, ensuring consistency in data usage and interpretation. They support database management, data governance, and facilitate communication among stakeholders.
Master Data
Definition: Master data represents the core data entities that are essential for business operations, such as customers, products, employees, and suppliers. It is a single source of truth for these key entities.
Usage: Master data management (MDM) ensures data consistency, accuracy, and reliability across different systems and processes, supporting operational efficiency and decision-making.
Common Data Model (CDM)
Definition: A common data model is a standardised framework for organising and structuring data across disparate systems and platforms, enabling data interoperability and consistency.
Usage: CDMs facilitate data integration, sharing, and analysis across different applications and organisations, enhancing data governance and reducing data silos.
Data Lake
Definition: A data lake is a centralised repository that stores raw, unprocessed data in its native format, including structured, semi-structured, and unstructured data.
Usage: Data lakes enable large-scale data storage and processing, supporting advanced analytics, machine learning, and big data initiatives. They offer flexibility in data ingestion and analysis.
Data Warehouse
Definition: A data warehouse is a centralised repository that stores processed and structured data from multiple sources, optimised for query and analysis.
Usage: Data warehouses support business intelligence, reporting, and data analytics by providing a consolidated view of historical data, facilitating decision-making and strategic planning.
Data Lakehouse
Definition: A data lakehouse is a modern data management architecture that combines the capabilities of data lakes and data warehouses. It integrates the flexibility and scalability of data lakes with the data management and ACID (Atomicity, Consistency, Isolation, Durability) transaction support of data warehouses.
Usage: Data lakehouses provide a unified platform for data storage, processing, and analytics. They allow organisations to store raw and processed data in a single location, making it easier to perform data engineering, data science, and business analytics. The architecture supports both structured and unstructured data, enabling advanced analytics and machine learning workflows while ensuring data integrity and governance.
Data Mart
Definition: A data mart is a subset of a data warehouse that is focused on a specific business line, department, or subject area. It contains a curated collection of data tailored to meet the specific needs of a particular group of users within an organisation.
Usage: Data marts are used to provide a more accessible and simplified view of data for specific business functions, such as sales, finance, or marketing. By focusing on a narrower scope of data, data marts allow for quicker query performance and more relevant data analysis for the target users. They support tactical decision-making by enabling departments to access the specific data they need without sifting through the entire data warehouse. Data marts can be implemented using star schema or snowflake schema to optimize data retrieval and analysis.
Data Lineage
Definition: Data lineage refers to the tracking and visualisation of data as it flows from its source to its destination, showing how data is transformed, processed, and used over time.
Usage: Data lineage provides transparency into data processes, supporting data governance, compliance, and troubleshooting. It helps understand data origin, transformations, and data usage across the organisation.
Dependencies and Sequence in the Data Life Cycle
Data Collection and Ingestion – Data is collected from various sources and ingested into a data lake for storage in its raw format.
Data Cataloguing and Metadata Management – A data catalogue is used to inventory and organise data assets in the data lake, providing metadata and improving data discoverability. The data catalogue often includes data lineage information to track data flows and transformations.
Data Classification and Taxonomy – Data is categorised using a data taxonomy to facilitate organisation and retrieval, ensuring data is easily accessible and understandable.
Data Structuring and Integration – Relevant data is structured and integrated into a common data model to ensure consistency and interoperability across systems.
Master Data Management – Master data is identified, cleansed, and managed to ensure consistency and accuracy across into the datawarehouse and other systems.
Data Transformation and Loading – Data is processed, transformed, and loaded into a data warehouse for efficient querying and analysis.
Focused Data Subset – Data relevant to and required for business a sepcific domain i.e. Financial data analytics and reporting are augmented into a Domain Specific Data Mart.
Data Dictionary Creation – A data dictionary is developed to provide detailed metadata about the structured data, supporting accurate data usage and interpretation.
Data Lineage Tracking – Throughout the data lifecycle, data lineage is tracked to document the origin, transformations, and usage of data, ensuring transparency and aiding in compliance and governance.
Data Utilisation and Analysis – Structured data in the data warehouse and/or data mart is used for business intelligence, reporting, and analytics, driving insights and decision-making.
Summary of Dependencies
Data Sources → Data Catalogue → Data Taxonomy → Data Dictionary → Master Data → Common Data Model → Data Lineage → Data Lake → Data Warehouse → Data Lakehouse → Data Mart → Reports & Dashboards
Data Lake: Initial storage for raw data.
Data Catalogue: Provides metadata, including data lineage, and improves data discoverability in the data lake.
Data Taxonomy: Organises data for better accessibility and understanding.
Common Data Model: Standardises data structure for integration and interoperability.
Data Dictionary: Documents metadata for structured data.
Data Lakehouse: Integrates the capabilities of data lakes and data warehouses, supporting efficient data processing and analysis.
Data Warehouse: Stores processed data for analysis and reporting.
Data Mart: Focused subset of the data warehouse tailored for specific business lines or departments.
Master Data: Ensures consistency and accuracy of key business entities across systems.
Data Lineage: Tracks data flows and transformations throughout the data lifecycle, supporting governance and compliance.
Each component plays a crucial role in the data lifecycle, with dependencies that ensure data is efficiently collected, managed, and utilised for business value. The inclusion of Data Lakehouse and Data Mart enhances the architecture by providing integrated, flexible, and focused data management solutions, supporting advanced analytics and decision-making processes. Data lineage, in particular, provides critical insights into the data’s journey, enhancing transparency and trust in data processes.
Tooling for key data management components
Selecting the right tools to govern, protect, and manage data is paramount for organisations aiming to maximise the value of their data assets. Microsoft Purview and CluedIn are two leading solutions that offer comprehensive capabilities in this domain. This comparison table provides a detailed analysis of how each platform addresses key data management components, including data catalogues, taxonomies, common data models, data dictionaries, master data, data lineage, data lakes, data warehouses, data lakehouses, and data marts. By understanding the strengths and functionalities of Microsoft Purview and CluedIn, organisations can make informed decisions to enhance their data management strategies and achieve better business outcomes.
Data Management Component
Microsoft Purview
CluedIn
Data Catalogue
Provides a unified data catalog that captures and describes data metadata automatically. Facilitates data discovery and governance with a business glossary and technical search terms.
Offers a comprehensive data catalog with metadata management, improving discoverability and governance of data assets across various sources.
Data Taxonomy
Supports data classification and organization using built-in and custom classifiers. Enhances data discoverability through a structured taxonomy.
Enables data classification and organization using vocabularies and custom taxonomies. Facilitates better data understanding and accessibility.
Common Data Model (CDM)
Facilitates data integration and interoperability by supporting standard data models and classifications. Integrates with Microsoft Dataverse.
Natively supports the Common Data Model and integrates seamlessly with Microsoft Dataverse and other Azure services, ensuring flexible data integration.
Data Dictionary
Functions as a detailed data dictionary through its data catalog, documenting metadata for structured data and providing detailed descriptions.
Provides a data dictionary through comprehensive metadata management, documenting and describing data elements across systems.
Data Lineage
Offers end-to-end data lineage, visualizing data flows across various platforms like Data Factory, Azure Synapse, and Power BI.
Provides detailed data lineage tracking, extending Purview’s lineage capabilities with additional processing logs and insights.
Data Lake
Integrates with Azure Data Lake, managing metadata and governance policies to ensure consistency and compliance.
Supports integration with data lakes, managing and governing the data stored within them through comprehensive metadata management.
Data Warehouse
Supports data warehouses by cataloging and managing metadata for structured data used in analytics and business intelligence.
Integrates with data warehouses, ensuring data governance and quality management, and supporting analytics with tools like Azure Synapse and Power BI.
Data Lakehouse
Not explicitly defined as a data lakehouse, but integrates capabilities of data lakes and warehouses to support hybrid data environments.
Integrates with both data lakes and data warehouses, effectively supporting the data lakehouse model for seamless data management and governance.
Master Data
Manages master data effectively by ensuring consistency and accuracy across systems through robust governance and classification.
Excels in master data management by consolidating, cleansing, and connecting data sources into a unified view, ensuring data quality and reliability.
Data Governance
Provides comprehensive data governance solutions, including automated data discovery, classification, and policy enforcemen.
Offers robust data governance features, integrating with Azure Purview for enhanced governance capabilities and compliance tracking.
Data governance tooling: Purview vs CluedIn
Conclusion
Navigating the complexities of data management requires a thorough understanding of the various components and their roles within the data lifecycle. From initial data collection and ingestion into data lakes to the structuring and integration within common data models and the ultimate utilisation in data warehouses and data marts, each component serves a distinct purpose. Effective data management solutions like Microsoft Purview and CluedIn exemplify how these components can be integrated to provide robust governance, ensure data quality, and facilitate advanced analytics. By leveraging these tools and understanding their interdependencies, organisations can build a resilient data infrastructure that supports informed decision-making, drives innovation, and maintains regulatory compliance.
In every business today, data has become one of the most valuable assets for organisations across all industries. However, managing this data responsibly and effectively presents a myriad of challenges, especially given the complex landscape of global data privacy laws. Here, we delve into the crucial aspects of data governance and how various international data protection regulations influence organisational strategies.
Essentials of Data Governance
Data governance encompasses the overall management of the availability, usability, integrity, and security of the data employed in an enterprise. A robust data governance programme focuses on several key areas:
Data Quality: Ensuring the accuracy, completeness, consistency, and reliability of data throughout its lifecycle. This involves setting standards and procedures for data entry, maintenance, and removal.
Data Security: Protecting data from unauthorised access and breaches. This includes implementing robust security measures such as encryption, access controls, and regular audits.
Compliance: Adhering to relevant laws and regulations that govern data protection and privacy, such as GDPR, HIPAA, or CCPA. This involves keeping up to date with legal requirements and implementing policies and procedures to ensure compliance.
Data Accessibility: Making data available to stakeholders in an organised manner that respects security and privacy constraints. This includes defining who can access data, under what conditions, and ensuring that the data can be easily and efficiently retrieved.
Data Lifecycle Management: Managing the flow of an organisation’s data from creation and initial storage to the time when it becomes obsolete and is deleted. This includes policies on data retention, archiving, and disposal.
Data Architecture and Integration: Structuring data architecture so that it supports an organisation’s information needs. This often involves integrating data from multiple sources and ensuring that it is stored in formats that are suitable for analysis and decision-making.
Master Data Management: The process of managing, centralising, organising, categorising, localising, synchronising, and enriching master data according to the business rules of a company or enterprise.
Metadata Management: Keeping a catalogue of metadata to help manage data assets by making it easier to locate and understand data stored in various systems throughout the organisation.
Change Management: Managing changes to the data environment in a controlled manner to prevent disruptions to the business and to maintain data integrity and accuracy.
Data Literacy: Promoting data literacy among employees to enhance their understanding of data principles and practices, which can lead to better decision-making throughout the organisation.
By focusing on these areas, organisations can maximise the value of their data, reduce risks, and ensure that data management practices support their business objectives and regulatory requirements.
Understanding Global Data Privacy Laws
As data flows seamlessly across borders, understanding and complying with various data privacy laws become paramount. Here’s a snapshot of some of the significant data privacy regulations around the globe:
General Data Protection Regulation (GDPR): The cornerstone of data protection in the European Union, GDPR sets stringent guidelines for data handling and grants significant rights to individuals over their personal data.
California Consumer Privacy Act (CCPA) and California Privacy Rights Act (CPRA): These laws provide broad privacy rights and are among the most stringent in the United States.
Personal Information Protection and Electronic Documents Act (PIPEDA) in Canada and Lei Geral de Proteção de Dados (LGPD) in Brazil reflect the growing trend of adopting GDPR-like standards.
UK General Data Protection Regulation (UK GDPR), post-Brexit, which continues to protect data in alignment with the EU’s standards.
Personal Information Protection Law (PIPL) in China, which indicates a significant step towards stringent data protection norms akin to GDPR.
These regulations underscore the need for robust data governance frameworks that not only comply with legal standards but also protect organisations from financial and reputational harm.
The USA and other countries have various regulations that address data privacy, though they often differ in scope and approach from the European and UK’s GDPR. Here’s an overview of some of these regulations:
United States
The USA does not have a single, comprehensive federal law governing data privacy akin to the GDPR. Instead, it has a patchwork of federal and state laws that address different aspects of privacy:
Health Insurance Portability and Accountability Act (HIPAA): Protects medical information.
Children’s Online Privacy Protection Act (COPPA): Governs the collection of personal information from children under the age of 13.
California Consumer Privacy Act (CCPA) and California Privacy Rights Act (CPRA): These state laws resemble the GDPR more closely than other US laws, providing broad privacy rights concerning personal information.
Virginia Consumer Data Protection Act (VCDPA) and Colorado Privacy Act (CPA): Similar to the CCPA, these state laws offer consumers certain rights over their personal data.
European Union
General Data Protection Regulation (GDPR): This is the primary law regulating how companies protect EU citizens’ personal data. GDPR has set a benchmark globally for data protection and privacy laws.
United Kingdom
UK General Data Protection Regulation (UK GDPR): Post-Brexit, the UK has retained the EU GDPR in domestic law but has made some technical changes. It operates alongside the Data Protection Act 2018.
Canada
Personal Information Protection and Electronic Documents Act (PIPEDA): Governs how private sector organisations collect, use, and disclose personal information in the course of commercial business.
Australia
Privacy Act 1988 (including the Australian Privacy Principles): Governs the handling of personal information by most federal government agencies and some private sector organisations.
Brazil
Lei Geral de Proteção de Dados (LGPD): Brazil’s LGPD shares many similarities with the GDPR and is designed to unify 40 different statutes that previously regulated personal data in Brazil.
Japan
Act on the Protection of Personal Information (APPI): Japan’s APPI was amended to strengthen data protection standards and align more closely with international standards, including the GDPR.
China
Personal Information Protection Law (PIPL): Implemented in 2021, this law is part of China’s framework of laws aimed at regulating cyberspace and protecting personal data similarly to the GDPR.
India
Personal Data Protection Bill (PDPB): As of the latest updates, this bill is still in the process of being finalised and aims to provide a comprehensive data protection framework in India. This will become the Personal Data Protection Act (PDPA).
Sri Lanka
Sri Lanka welcomed the Personal Data Protection Act No. 09 of 2022 (the “Act”) in March 2022.
The PDPA aims to regulate the processing of personal data and protect the rights of data subjects. It will establish principles for data collection, processing, and storage, as well as define the roles of data controllers and processors.
During drafting, the committee considered international best practices, including the OECD Privacy Guidelines, APEC Privacy Framework, EU GDPR, and other data protection laws.
Each of these laws has its own unique set of requirements and protections, and businesses operating in these jurisdictions need to ensure they comply with the relevant legislation.
How data privacy legislation impacts data governance
Compliance with these regulations requires a comprehensive data governance framework that includes policies, procedures, roles, and responsibilities designed to ensure that data is managed in a way that respects individual privacy rights and complies with legal obligations. GDPR (General Data Protection Regulation) and other data privacy legislation play a critical role in shaping data governance strategies. Compliance with these regulations is essential for organisations, particularly those that handle personal data of individuals within the jurisdictions covered by these laws. Here’s how :
Data Protection by Design and by Default: GDPR and similar laws require organisations to integrate data protection into their processing activities and business practices, from the earliest design stages all the way through the lifecycle of the data. This means considering privacy in the initial design of systems and processes and ensuring that personal data is processed with the highest privacy settings by default.
Lawful Basis for Processing: Organisations must identify a lawful basis for processing personal data, such as consent, contractual necessity, legal obligations, vital interests, public interest, or legitimate interests. This requires careful analysis and documentation to ensure that the basis is appropriate and that privacy rights are respected.
Data Subject Rights: Data privacy laws typically grant individuals rights over their data, including the right to access, rectify, delete, or transfer their data (right to portability), and the right to object to certain types of processing. Data governance frameworks must include processes to address these rights promptly and effectively.
Data Minimization and Limitation: Privacy regulations often emphasize that organisations should collect only the data that is necessary for a specified purpose and retain it only as long as it is needed for that purpose. This requires clear data retention policies and procedures to ensure compliance and reduce risk.
Cross-border Data Transfers: GDPR and other regulations have specific requirements regarding the transfer of personal data across borders. Organisations must ensure that they have legal mechanisms in place, such as Standard Contractual Clauses (SCCs) or adherence to international frameworks like the EU-U.S. Privacy Shield.
Breach Notification: Most privacy laws require organisations to notify regulatory authorities and, in some cases, affected individuals of data breaches within a specific timeframe. Data governance policies must include breach detection, reporting, and investigation procedures to comply with these requirements.
Data Protection Officer (DPO): GDPR and certain other laws require organisations to appoint a Data Protection Officer if they engage in significant processing of personal data. The DPO is responsible for overseeing data protection strategies, compliance, and education.
Record-Keeping: Organisations are often required to maintain detailed records of data processing activities, including the purpose of processing, data categories processed, data recipient categories, and the envisaged retention times for different data categories.
Impact Assessments: GDPR mandates Data Protection Impact Assessments (DPIAs) for processing that is likely to result in high risks to individuals’ rights and freedoms. These assessments help organisations identify, minimize, and mitigate data protection risks.
Strategic Implications for Organisations
Organisations must integrate data protection principles early in the design phase of their projects and ensure that personal data is processed with high privacy settings by default. A lawful basis for processing data must be clearly identified and documented. Furthermore, data protection officers (DPOs) may need to be appointed to oversee compliance, particularly in large organisations or those handling sensitive data extensively.
Conclusion
Adopting a comprehensive data governance strategy is not merely about legal compliance, it is about building trust with customers and stakeholders, enhancing the operational effectiveness of the organisation, and securing a competitive advantage in the marketplace. By staying informed and agile, organisations can navigate the complexities of data governance and global privacy regulations effectively, ensuring sustainable and ethical use of their valuable data resources.