Data lineage refers to the lifecycle of data as it travels through various processes in an information system. It is a comprehensive account or visualisation of where data originates, where it moves, and how it changes throughout its journey within an organisation. Essentially, data lineage provides a clear map or trace of the data’s journey from its source to its destination, including all the transformations it undergoes along the way.
Here are some key aspects of data lineage:
Source of Data: Data lineage begins by identifying the source of the data, whether it’s from internal databases, external data sources, or real-time data streams.
Data Transformations: It records each process or transformation the data undergoes, such as data cleansing, aggregation, and merging. This helps in understanding how the data is manipulated and refined.
Data Movement: The path that data takes through different systems and processes is meticulously traced. This includes its movement across databases, servers, and applications within an organisation.
Final Destination: Data lineage includes tracking the data to its final destination, which might be a data warehouse, report, or any other endpoint where the data is stored or utilised.
Importance of Data Lineage
Data lineage is crucial for several reasons:
Transparency and Trust: It helps build confidence in data quality and accuracy by providing transparency on how data is handled and transformed.
Compliance and Auditing: Many industries are subject to stringent regulatory requirements concerning data handling, privacy, and reporting. Data lineage allows for compliance tracking and simplifies the auditing process by providing a clear trace of data handling practices.
Error Tracking and Correction: By understanding how data flows through systems, it becomes easier to identify the source of errors or discrepancies and correct them, thereby improving overall data quality.
Impact Analysis: Data lineage is essential for impact analysis, enabling organisations to assess the potential effects of changes in data sources or processing algorithms on downstream systems and processes.
Data Governance: Effective data governance relies on clear data lineage to enforce policies and rules regarding data access, usage, and security.
Tooling
Data lineage tools are essential for tracking the flow of data through various systems and transformations, providing transparency and facilitating better data management practices. Here’s a list of popular technology tools that can be used for data lineage:
Informatica: A leader in data integration, Informatica offers powerful tools for managing data lineage, particularly with its Enterprise Data Catalogue, which helps organisations to discover and inventory data assets across the system.
IBM InfoSphere Information Governance Catalogue: IBM’s solution provides extensive features for data governance, including data lineage. It helps users understand data origin, usage, and transformation within their enterprise environments.
Talend: Talend’s Data Fabric includes data lineage capabilities that help map and visualise the flow of data through different systems, helping with compliance, data governance, and data quality management.
Collibra: Collibra is known for its data governance and catalogue software that supports data lineage visualisation to manage compliance, data quality, and data usage across the organisation.
Apache Atlas: Part of the Hadoop ecosystem, Apache Atlas provides open-source tools for metadata management and data governance, including data lineage for complex data environments.
Alation: Alation offers a data catalogue tool that includes data lineage features, providing insights into data origin, context, and usage, which is beneficial for data governance and compliance.
MANTA: MANTA focuses specifically on data lineage and provides visualisation tools that help organisations map out and understand their data flows and transformations.
erwin Data Intelligence: erwin provides robust data modelling and metadata management solutions, including data lineage tools to help organisations understand the flow of data within their IT ecosystems.
Microsoft Purview: This is a unified data governance service that helps manage and govern on-premises, multi-cloud, and software-as-a-service (SaaS) data. It includes automated data discovery, sensitivity classification, access controls and end-to-end data lineage.
Google Cloud Data Catalogue: A fully managed and scalable metadata management service that allows organisations to quickly discover, manage, and understand their Google Cloud data assets. It includes data lineage capabilities to visualise relationships and data flows.
These tools cater to a variety of needs, from large enterprises to more specific requirements like compliance and data quality management. They can help organisations ensure that their data handling practices are transparent, efficient, and compliant with relevant regulations.
In summary, data lineage acts as a critical component of data management and governance frameworks, providing a clear and accountable method of tracking data from its origin through all its transformations and uses. This tracking is indispensable for maintaining the integrity, reliability, and trustworthiness of data in complex information systems.
In the contemporary landscape of data-driven decision-making, robust data management practices are critical for organisations seeking to harness the full potential of their data assets. Effective data management encompasses various components, each playing a vital role in ensuring data integrity, accessibility, and usability.
Key components such as data catalogues, taxonomies, common data models, data dictionaries, master data, data lineage, data lakes, data warehouses, data lakehouses, and data marts, along with their interdependencies and sequences within the data lifecycle, form the backbone of a sound data management strategy.
This cocise guide explores these components in detail, elucidating their definitions, uses, and how they interrelate to support seamless data management throughout the data lifecycle.
Definitions and Usage of Key Data Management Components
Data Catalogue
Definition: A data catalogue is a comprehensive inventory of data assets within an organisation. It provides metadata, data classification, and information on data lineage, data quality, and data governance.
Usage: Data catalogues help data users discover, understand, and manage data. They enable efficient data asset management and ensure compliance with data governance policies.
Data Taxonomy
Definition: Data taxonomy is a hierarchical structure that organises data into categories and subcategories based on shared characteristics or business relevance.
Usage: It facilitates data discovery, improves data quality, and aids in the consistent application of data governance policies by providing a clear structure for data classification.
Data Dictionary
Definition: A data dictionary is a centralised repository that describes the structure, content, and relationships of data elements within a database or information system.
Usage: Data dictionaries provide metadata about data, ensuring consistency in data usage and interpretation. They support database management, data governance, and facilitate communication among stakeholders.
Master Data
Definition: Master data represents the core data entities that are essential for business operations, such as customers, products, employees, and suppliers. It is a single source of truth for these key entities.
Usage: Master data management (MDM) ensures data consistency, accuracy, and reliability across different systems and processes, supporting operational efficiency and decision-making.
Common Data Model (CDM)
Definition: A common data model is a standardised framework for organising and structuring data across disparate systems and platforms, enabling data interoperability and consistency.
Usage: CDMs facilitate data integration, sharing, and analysis across different applications and organisations, enhancing data governance and reducing data silos.
Data Lake
Definition: A data lake is a centralised repository that stores raw, unprocessed data in its native format, including structured, semi-structured, and unstructured data.
Usage: Data lakes enable large-scale data storage and processing, supporting advanced analytics, machine learning, and big data initiatives. They offer flexibility in data ingestion and analysis.
Data Warehouse
Definition: A data warehouse is a centralised repository that stores processed and structured data from multiple sources, optimised for query and analysis.
Usage: Data warehouses support business intelligence, reporting, and data analytics by providing a consolidated view of historical data, facilitating decision-making and strategic planning.
Data Lakehouse
Definition: A data lakehouse is a modern data management architecture that combines the capabilities of data lakes and data warehouses. It integrates the flexibility and scalability of data lakes with the data management and ACID (Atomicity, Consistency, Isolation, Durability) transaction support of data warehouses.
Usage: Data lakehouses provide a unified platform for data storage, processing, and analytics. They allow organisations to store raw and processed data in a single location, making it easier to perform data engineering, data science, and business analytics. The architecture supports both structured and unstructured data, enabling advanced analytics and machine learning workflows while ensuring data integrity and governance.
Data Mart
Definition: A data mart is a subset of a data warehouse that is focused on a specific business line, department, or subject area. It contains a curated collection of data tailored to meet the specific needs of a particular group of users within an organisation.
Usage: Data marts are used to provide a more accessible and simplified view of data for specific business functions, such as sales, finance, or marketing. By focusing on a narrower scope of data, data marts allow for quicker query performance and more relevant data analysis for the target users. They support tactical decision-making by enabling departments to access the specific data they need without sifting through the entire data warehouse. Data marts can be implemented using star schema or snowflake schema to optimize data retrieval and analysis.
Data Lineage
Definition: Data lineage refers to the tracking and visualisation of data as it flows from its source to its destination, showing how data is transformed, processed, and used over time.
Usage: Data lineage provides transparency into data processes, supporting data governance, compliance, and troubleshooting. It helps understand data origin, transformations, and data usage across the organisation.
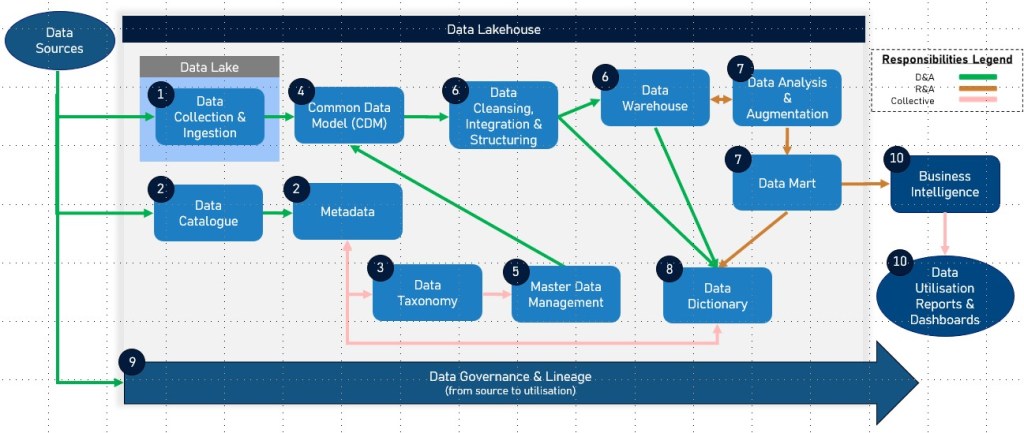
Dependencies and Sequence in the Data Life Cycle
Data Collection and Ingestion – Data is collected from various sources and ingested into a data lake for storage in its raw format.
Data Cataloguing and Metadata Management – A data catalogue is used to inventory and organise data assets in the data lake, providing metadata and improving data discoverability. The data catalogue often includes data lineage information to track data flows and transformations.
Data Classification and Taxonomy – Data is categorised using a data taxonomy to facilitate organisation and retrieval, ensuring data is easily accessible and understandable.
Data Structuring and Integration – Relevant data is structured and integrated into a common data model to ensure consistency and interoperability across systems.
Master Data Management – Master data is identified, cleansed, and managed to ensure consistency and accuracy across into the datawarehouse and other systems.
Data Transformation and Loading – Data is processed, transformed, and loaded into a data warehouse for efficient querying and analysis.
Focused Data Subset – Data relevant to and required for business a sepcific domain i.e. Financial data analytics and reporting are augmented into a Domain Specific Data Mart.
Data Dictionary Creation – A data dictionary is developed to provide detailed metadata about the structured data, supporting accurate data usage and interpretation.
Data Lineage Tracking – Throughout the data lifecycle, data lineage is tracked to document the origin, transformations, and usage of data, ensuring transparency and aiding in compliance and governance.
Data Utilisation and Analysis – Structured data in the data warehouse and/or data mart is used for business intelligence, reporting, and analytics, driving insights and decision-making.
Summary of Dependencies
Data Sources → Data Catalogue → Data Taxonomy → Data Dictionary → Master Data → Common Data Model → Data Lineage → Data Lake → Data Warehouse → Data Lakehouse → Data Mart → Reports & Dashboards
Data Lake: Initial storage for raw data.
Data Catalogue: Provides metadata, including data lineage, and improves data discoverability in the data lake.
Data Taxonomy: Organises data for better accessibility and understanding.
Common Data Model: Standardises data structure for integration and interoperability.
Data Dictionary: Documents metadata for structured data.
Data Lakehouse: Integrates the capabilities of data lakes and data warehouses, supporting efficient data processing and analysis.
Data Warehouse: Stores processed data for analysis and reporting.
Data Mart: Focused subset of the data warehouse tailored for specific business lines or departments.
Master Data: Ensures consistency and accuracy of key business entities across systems.
Data Lineage: Tracks data flows and transformations throughout the data lifecycle, supporting governance and compliance.
Each component plays a crucial role in the data lifecycle, with dependencies that ensure data is efficiently collected, managed, and utilised for business value. The inclusion of Data Lakehouse and Data Mart enhances the architecture by providing integrated, flexible, and focused data management solutions, supporting advanced analytics and decision-making processes. Data lineage, in particular, provides critical insights into the data’s journey, enhancing transparency and trust in data processes.
Tooling for key data management components
Selecting the right tools to govern, protect, and manage data is paramount for organisations aiming to maximise the value of their data assets. Microsoft Purview and CluedIn are two leading solutions that offer comprehensive capabilities in this domain. This comparison table provides a detailed analysis of how each platform addresses key data management components, including data catalogues, taxonomies, common data models, data dictionaries, master data, data lineage, data lakes, data warehouses, data lakehouses, and data marts. By understanding the strengths and functionalities of Microsoft Purview and CluedIn, organisations can make informed decisions to enhance their data management strategies and achieve better business outcomes.
Data Management Component
Microsoft Purview
CluedIn
Data Catalogue
Provides a unified data catalog that captures and describes data metadata automatically. Facilitates data discovery and governance with a business glossary and technical search terms.
Offers a comprehensive data catalog with metadata management, improving discoverability and governance of data assets across various sources.
Data Taxonomy
Supports data classification and organization using built-in and custom classifiers. Enhances data discoverability through a structured taxonomy.
Enables data classification and organization using vocabularies and custom taxonomies. Facilitates better data understanding and accessibility.
Common Data Model (CDM)
Facilitates data integration and interoperability by supporting standard data models and classifications. Integrates with Microsoft Dataverse.
Natively supports the Common Data Model and integrates seamlessly with Microsoft Dataverse and other Azure services, ensuring flexible data integration.
Data Dictionary
Functions as a detailed data dictionary through its data catalog, documenting metadata for structured data and providing detailed descriptions.
Provides a data dictionary through comprehensive metadata management, documenting and describing data elements across systems.
Data Lineage
Offers end-to-end data lineage, visualizing data flows across various platforms like Data Factory, Azure Synapse, and Power BI.
Provides detailed data lineage tracking, extending Purview’s lineage capabilities with additional processing logs and insights.
Data Lake
Integrates with Azure Data Lake, managing metadata and governance policies to ensure consistency and compliance.
Supports integration with data lakes, managing and governing the data stored within them through comprehensive metadata management.
Data Warehouse
Supports data warehouses by cataloging and managing metadata for structured data used in analytics and business intelligence.
Integrates with data warehouses, ensuring data governance and quality management, and supporting analytics with tools like Azure Synapse and Power BI.
Data Lakehouse
Not explicitly defined as a data lakehouse, but integrates capabilities of data lakes and warehouses to support hybrid data environments.
Integrates with both data lakes and data warehouses, effectively supporting the data lakehouse model for seamless data management and governance.
Master Data
Manages master data effectively by ensuring consistency and accuracy across systems through robust governance and classification.
Excels in master data management by consolidating, cleansing, and connecting data sources into a unified view, ensuring data quality and reliability.
Data Governance
Provides comprehensive data governance solutions, including automated data discovery, classification, and policy enforcemen.
Offers robust data governance features, integrating with Azure Purview for enhanced governance capabilities and compliance tracking.
Data governance tooling: Purview vs CluedIn
Conclusion
Navigating the complexities of data management requires a thorough understanding of the various components and their roles within the data lifecycle. From initial data collection and ingestion into data lakes to the structuring and integration within common data models and the ultimate utilisation in data warehouses and data marts, each component serves a distinct purpose. Effective data management solutions like Microsoft Purview and CluedIn exemplify how these components can be integrated to provide robust governance, ensure data quality, and facilitate advanced analytics. By leveraging these tools and understanding their interdependencies, organisations can build a resilient data infrastructure that supports informed decision-making, drives innovation, and maintains regulatory compliance.