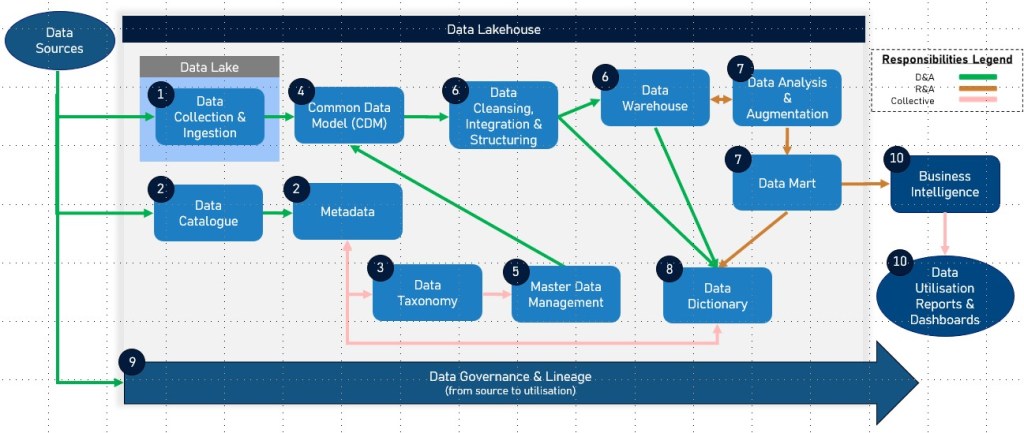
With data being the live blood of organisations the emphasis on data management places organisations on a continuous search for innovative approaches to harness and optimise the power of their data assets. In this pursuit, the bimodal model is a well established strategy that can be successfully employed by data-driven enterprises. This approach, which combines the stability of traditional data management with the agility of modern data practices, while providing a delivery methodology facilitating rapid innovation and resilient technology service provision.
Understanding the Bimodal Model
Gartner states: “Bimodal IT is the practice of managing two separate, coherent modes of IT delivery, one focused on stability and the other on agility. Mode 1 is traditional and sequential, emphasising safety and accuracy. Mode 2 is exploratory and nonlinear, emphasising agility and speed.
At its core, the bimodal model advocates for a dual approach to data management. Mode 1 focuses on the stable, predictable aspects of data, ensuring the integrity, security, and reliability of core business processes. This mode aligns with traditional data management practices, where accuracy and consistency are paramount. On the other hand, Mode 2 emphasizes agility, innovation, and responsiveness to change. It enables organizations to explore emerging technologies, experiment with new data sources, and adapt swiftly to evolving business needs.
Benefits of Bimodal Data Management
1. Optimised Performance and Stability: Mode 1 ensures that essential business functions operate smoothly, providing a stable foundation for the organization.
Mode 1 of the bimodal model is dedicated to maintaining the stability and reliability of core business processes. This is achieved through robust data governance, stringent quality controls, and established best practices in data management. By ensuring the integrity of data and the reliability of systems, organizations can optimise the performance of critical operations. This stability is especially crucial for industries where downtime or errors can have significant financial or operational consequences, such as finance, healthcare, and manufacturing.
Example: In the financial sector, a major bank implemented the bimodal model to enhance its core banking operations. Through Mode 1, the bank ensured the stability of its transaction processing systems, reducing system downtime by 20% and minimizing errors in financial transactions. This stability not only improved customer satisfaction but also resulted in a 15% increase in operational efficiency, as reported in the bank’s annual report.
2. Innovation and Agility: Mode 2 allows businesses to experiment with cutting-edge technologies like AI, machine learning, and big data analytics, fostering innovation and agility in decision-making processes.
Mode 2 is the engine of innovation within the bimodal model. It provides the space for experimentation with emerging technologies and methodologies. Businesses can leverage AI, machine learning, and big data analytics to uncover new insights, identify patterns, and make informed decisions. This mode fosters agility by encouraging a culture of continuous improvement and adaptation to technological advancements. It enables organizations to respond quickly to market trends, customer preferences, and competitive challenges, giving them a competitive edge in dynamic industries.
Example: A leading e-commerce giant adopted the bimodal model to balance stability and innovation in its operations. Through Mode 2, the company integrated machine learning algorithms into its recommendation engine. As a result, the accuracy of personalized product recommendations increased by 25%, leading to a 10% rise in customer engagement and a subsequent 12% growth in overall sales. This successful integration of Mode 2 practices directly contributed to the company’s market leadership in the highly competitive online retail space.
3. Enhanced Scalability: The bimodal approach accommodates the scalable growth of data-driven initiatives, ensuring that the organization can handle increased data volumes efficiently.
In the modern data landscape, the volume of data generated is growing exponentially. Mode 1 ensures that foundational systems are equipped to handle increasing data loads without compromising performance or stability. Meanwhile, Mode 2 facilitates the implementation of scalable technologies and architectures, such as cloud computing and distributed databases. This combination allows organizations to seamlessly scale their data infrastructure, supporting the growth of data-driven initiatives without experiencing bottlenecks or diminishing performance.
Example: A global technology firm leveraged the bimodal model to address the challenges of data scalability in its cloud-based services. In Mode 1, the company optimized its foundational cloud infrastructure, ensuring uninterrupted service during periods of increased data traffic. Simultaneously, through Mode 2 practices, the firm adopted containerization and microservices architecture, resulting in a 30% improvement in scalability. This enhanced scalability enabled the company to handle a 50% surge in user data without compromising performance, leading to increased customer satisfaction and retention.
4. Faster Time-to-Insights: By leveraging Mode 2 practices, organizations can swiftly analyze new data sources, enabling faster extraction of valuable insights for strategic decision-making.
Mode 2 excels in rapidly exploring and analyzing new and diverse data sources. This capability significantly reduces the time it takes to transform raw data into actionable insights. Whether it’s customer feedback, market trends, or operational metrics, Mode 2 practices facilitate agile and quick analysis. This speed in obtaining insights is crucial in fast-paced industries where timely decision-making is a competitive advantage.
Example: A healthcare organization implemented the bimodal model to expedite the analysis of patient data for clinical decision-making. Through Mode 2, the organization utilized advanced analytics and machine learning algorithms to process diagnostic data. The implementation led to a 40% reduction in the time required for diagnosis, enabling medical professionals to make quicker and more accurate decisions. This accelerated time-to-insights not only improved patient outcomes but also contributed to the organization’s reputation as a leader in adopting innovative healthcare technologies.
5. Adaptability in a Dynamic Environment: Bimodal data management equips organizations to adapt to market changes, regulatory requirements, and emerging technologies effectively.
In an era of constant change, adaptability is a key determinant of organizational success. Mode 2’s emphasis on experimentation and innovation ensures that organizations can swiftly adopt and integrate new technologies as they emerge. Additionally, the bimodal model allows organizations to navigate changing regulatory landscapes by ensuring that core business processes (Mode 1) comply with existing regulations while simultaneously exploring new approaches to meet evolving requirements. This adaptability is particularly valuable in industries facing rapid technological advancements or regulatory shifts, such as fintech, healthcare, and telecommunications.
Example: A telecommunications company embraced the bimodal model to navigate the dynamic landscape of regulatory changes and emerging technologies. In Mode 1, the company ensured compliance with existing telecommunications regulations. Meanwhile, through Mode 2, the organization invested in exploring and adopting 5G technologies. This strategic approach allowed the company to maintain regulatory compliance while positioning itself as an early adopter of 5G, resulting in a 25% increase in market share and a 15% growth in revenue within the first year of implementation.
Implementation Challenges and Solutions
Implementing a bimodal model in data management is not without its challenges. Legacy systems, resistance to change, and ensuring a seamless integration between modes can pose significant hurdles. However, these challenges can be overcome through a strategic approach that involves comprehensive training, fostering a culture of innovation, and investing in robust data integration tools.
1. Legacy Systems: Overcoming the Weight of Tradition
Challenge: Many organizations operate on legacy systems that are deeply ingrained in their processes. These systems, often built on older technologies, can be resistant to change, making it challenging to introduce the agility required by Mode 2.
Solution: A phased approach is crucial when dealing with legacy systems. Organizations can gradually modernize their infrastructure, introducing new technologies and methodologies incrementally. This could involve the development of APIs to bridge old and new systems, adopting microservices architectures, or even considering a hybrid cloud approach. Legacy system integration specialists can play a key role in ensuring a smooth transition and minimizing disruptions.
2. Resistance to Change: Shifting Organizational Mindsets
Challenge: Resistance to change is a common challenge when implementing a bimodal model. Employees accustomed to traditional modes of operation may be skeptical or uncomfortable with the introduction of new, innovative practices.
Solution: Fostering a culture of change is essential. This involves comprehensive training programs to upskill employees on new technologies and methodologies. Additionally, leadership plays a pivotal role in communicating the benefits of the bimodal model, emphasizing how it contributes to both stability and innovation. Creating cross-functional teams that include members from different departments and levels of expertise can also promote collaboration and facilitate a smoother transition.
3. Seamless Integration Between Modes: Ensuring Cohesion
Challenge: Integrating Mode 1 (stability-focused) and Mode 2 (innovation-focused) operations seamlessly can be complex. Ensuring that both modes work cohesively without compromising the integrity of data or system reliability is a critical challenge.
Solution: Implementing robust data governance frameworks is essential for maintaining cohesion between modes. This involves establishing clear protocols for data quality, security, and compliance. Organizations should invest in integration tools that facilitate communication and data flow between different modes. Collaboration platforms and project management tools that promote transparency and communication can bridge the gap between teams operating in different modes, fostering a shared understanding of goals and processes.
4. Lack of Skillset: Nurturing Expertise for Innovation
Challenge: Mode 2 often requires skills in emerging technologies such as artificial intelligence, machine learning, and big data analytics. Organizations may face challenges in recruiting or upskilling their workforce to meet the demands of this innovative mode.
Solution: Investing in training programs, workshops, and certifications can help bridge the skills gap. Collaboration with educational institutions or partnerships with specialized training providers can ensure that employees have access to the latest knowledge and skills. Creating a learning culture within the organization, where employees are encouraged to explore and acquire new skills, is vital for the success of Mode 2.
5. Overcoming Silos: Encouraging Cross-Functional Collaboration
Challenge: Siloed departments and teams can hinder the flow of information and collaboration between Mode 1 and Mode 2 operations. Communication breakdowns can lead to inefficiencies and conflicts.
Solution: Breaking down silos requires a cultural shift and the implementation of cross-functional teams. Encouraging open communication channels, regular meetings between teams from different modes, and fostering a shared sense of purpose can facilitate collaboration. Leadership should promote a collaborative mindset, emphasizing that both stability and innovation are integral to the organization’s success.
By addressing these challenges strategically, organizations can create a harmonious bimodal environment that combines the best of both worlds—ensuring stability in core operations while fostering innovation to stay ahead in the dynamic landscape of data-driven decision-making.
Case Studies: Bimodal Success Stories
Several forward-thinking organiSations have successfully implemented the bimodal model to enhance their data management capabilities. Companies like Netflix, Amazon, and Airbnb have embraced this approach, allowing them to balance stability with innovation, leading to improved customer experiences and increased operational efficiency.
Netflix: Balancing Stability and Innovation in Entertainment
Netflix, a pioneer in the streaming industry, has successfully implemented the bimodal model to revolutionize the way people consume entertainment. In Mode 1, Netflix ensures the stability of its streaming platform, focusing on delivering content reliably and securely. This includes optimizing server performance, ensuring data integrity, and maintaining a seamless user experience. Simultaneously, in Mode 2, Netflix harnesses the power of data analytics and machine learning to personalize content recommendations, optimize streaming quality, and forecast viewer preferences. This innovative approach has not only enhanced customer experiences but also allowed Netflix to stay ahead in a highly competitive and rapidly evolving industry.
Amazon: Transforming Retail with Data-Driven Agility
Amazon, a global e-commerce giant, employs the bimodal model to maintain the stability of its core retail operations while continually innovating to meet customer expectations. In Mode 1, Amazon focuses on the stability and efficiency of its e-commerce platform, ensuring seamless transactions and reliable order fulfillment. Meanwhile, in Mode 2, Amazon leverages advanced analytics and artificial intelligence to enhance the customer shopping experience. This includes personalized product recommendations, dynamic pricing strategies, and the use of machine learning algorithms to optimize supply chain logistics. The bimodal model has allowed Amazon to adapt to changing market dynamics swiftly, shaping the future of e-commerce through a combination of stability and innovation.
Airbnb: Personalizing Experiences through Data Agility
Airbnb, a disruptor in the hospitality industry, has embraced the bimodal model to balance the stability of its booking platform with continuous innovation in user experiences. In Mode 1, Airbnb ensures the stability and security of its platform, facilitating millions of transactions globally. In Mode 2, the company leverages data analytics and machine learning to personalize user experiences, providing tailored recommendations for accommodations, activities, and travel destinations. This approach not only enhances customer satisfaction but also allows Airbnb to adapt to evolving travel trends and preferences. The bimodal model has played a pivotal role in Airbnb’s ability to remain agile in a dynamic market while maintaining the reliability essential for its users.
Key Takeaways from Case Studies:
- Strategic Balance: Each of these case studies highlights the strategic balance achieved by these organizations through the bimodal model. They effectively manage the stability of core operations while innovating to meet evolving customer demands.
- Customer-Centric Innovation: The bimodal model enables organizations to innovate in ways that directly benefit customers. Whether through personalized content recommendations (Netflix), dynamic pricing strategies (Amazon), or tailored travel experiences (Airbnb), these companies use Mode 2 to create value for their users.
- Agile Response to Change: The case studies demonstrate how the bimodal model allows organizations to respond rapidly to market changes. Whether it’s shifts in consumer behavior, emerging technologies, or regulatory requirements, the dual approach ensures adaptability without compromising operational stability.
- Competitive Edge: By leveraging the bimodal model, these organizations gain a competitive edge in their respective industries. They can navigate challenges, seize opportunities, and continually evolve their offerings to stay ahead in a fast-paced and competitive landscape.
Conclusion
In the contemporary business landscape, characterised by the pivotal role of data as the cornerstone of organizational vitality, the bimodal model emerges as a strategic cornerstone for enterprises grappling with the intricacies of modern data management. Through the harmonious integration of stability and agility, organizations can unveil the full potential inherent in their data resources. This synergy propels innovation, enhances decision-making processes, and, fundamentally, positions businesses to achieve a competitive advantage within the dynamic and data-centric business environment. Embracing the bimodal model transcends mere preference; it represents a strategic imperative for businesses aspiring to not only survive but thrive in the digital epoch.
Also read – “How to Innovate to Stay Relevant“